 Спектральные методы обработки изображений
Спектральные методы обработки изображений
Цифровая обработка изображений не ограничивается задачами трансформации, которые были рассмотрены в предыдущем разделе. Важной составляющей является кодирование информации, то есть представление изображения в виде, который позволяет эффективное хранение и передачу графической информации, выделить те или иные характеристики, которые нужны при анализе объектов на данном изображении, определить наиболее информативные характеристики и прочее. Для этой цели используются частотные методы анализа, прежде всего это анализ Фурье и анализ главных компонент. Анализ Фурье может использовать тригонометрический базис, или базис с компактным носителем, что приведет к вейвлет-методам.
Прямое дискретное преобразование Фурье (ДПФ) и обратное ему преобразования, имеют стандартную форму \[ F(\nu)=N^{-1}\sum_{\tau=0}^{N-1}f(\tau)\exp\left(-i\frac{2\pi\nu \tau}{N}\right), f(\tau)=\sum_{\nu=0}^{N-1}F(\nu)\exp\left(i\frac{2\pi\nu \tau}{N}\right). \] Часто сигнал (изображение в том числе) нужно преобразовать только в действительной области, без использования комплексных переменных. В этом случае традиционным методом, который разделяет частотные характеристики сигнала является дискретное косинус преобразования (ДКП), из которого и начнем.
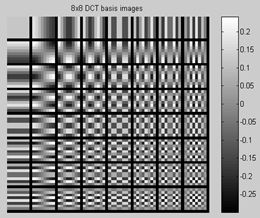
Рассмотрим одномерное ДКП для N = 8. Выбор такого значения N не случаен, в формате Jpeg изображение разбивается на квадраты 8 × 8, что и привело к тому, что говоря об использовании частотных методов в обработке изображений используют как раз такое число составляющих дискретного преобразования.
Выпишем прямое дискретное косинус преобразование \[ F_\nu=\frac{1}{\sqrt{2}}C_\nu\sum_{i=0}^7p_i\cos\frac{(2i+1)\nu\pi}{16},\\ C_i=\left\{ \begin{array}{ll} \frac{1}{\sqrt{2}}, &\hbox{i=0;} \\ 1, &\hbox{ i>0}. \end{array} \right. \] Обратное дискретное косинус преобразование \[ p_i=\frac{1}{\sqrt{2}}C_i\sum_{\nu=0}^7F_\nu\cos\frac{(2i+1)\nu\pi}{16}. \] Понятное дело, что кроме ДКТ существуют другие тригонометрические преобразования, например ДСП - дискретное синус преобразования или ДПХ - преобразование Хартли.
Этот вид преобразования назван в честь Р.Хартли, который в 1942 г. опубликовал статью о паре интегральных преобразований - прямое и обратное, использующих введенную им функцию \(\mathrm {cas} \theta = \sin \theta + \cos \theta \). К началу 1980-х годов эти результаты оставались в забвении, пока к ним не привлек внимание исследователей Р.Брейсуэлл, разработавший основы теории как непрерывного, так и дискретного преобразования Хартли.
Дискретное преобразование Хартли (ДПХ) действительной функции f(τ) и соответствующее обратное преобразование определяются соотношениями \[ H(\nu)=\frac{1}{N}\sum_{\tau=0}^{N-1}f(\tau)\mathrm{cas } \frac{2\pi\nu\tau}{N}, \] \[ f(\tau)=\sum_{\nu=0}^{N-1}H(\nu)\mathrm{cas } \frac{2\pi\nu\tau}{N}, \] где используется обозначение cas θ= cos θ+sin θ, введенное Хартли.
Для доказательства данного факта воспользуемся свойством ортогональности \[ \sum_{\nu=0}^{N-1}\mathrm{cas } \frac{2\pi\nu\tau}{N}\mathrm{cas } \frac{2\pi\nu t}{N} =\left\{ \begin{array}{ll} N, &\tau=t;\\ 0, &\tau\ne t. \end{array} \right. \] Подставляя величину \[ \frac{1}{N}\sum_{\tau=0}^{N-1}f(\tau)\mathrm{cas } \frac{2\pi\nu\tau}{N}, \] которая определяет преобразование H (v) , в выражение \[ \sum_{\nu=0}^{N-1}H(\nu)\mathrm{cas } \frac{2\pi\nu\tau}{N}, \] получаем \[ \sum_{\nu=0}^{N-1}H(\nu)\mathrm{cas } \frac{2\pi\nu\tau}{N}= \sum_{\nu=0}^{N-1}\frac{1}{N}\sum_{t=0}^{N-1}f(t)\mathrm{cas } \frac{2\pi\nu t}{N}\mathrm{cas } \frac{2\pi\nu\tau}{N}= \frac{1}{N}\sum_{t=0}^{N-1}f(t)\sum_{\nu=0}^{N-1}\mathrm{cas } \frac{2\pi\nu t}{N}\mathrm{cas } \frac{2\pi\nu\tau}{N}= \frac{1}{N}\sum_{t=0}^{N-1}f(t)\times \left\{ \begin{array}{ll} N, &\tau=t;\\ 0, &\tau\ne t \end{array} \right. =f(\tau). \] что подтверждает справедливость обратного преобразования.
Коэффициент \(N^{-1} \) в ДПХ заимствуется из практики использования ДПФ, для которого величина F (0) равна постоянной составляющей функции \(f (\tau) \), то есть, ДПХ является симметричной процедурой. Кроме этого, ДПХ является действительным преобразованием, поскольку действительной есть функция \(f (\tau) \).
Проведем сравнение приведенных дискретных преобразований на примере множества точек p = {12,10,8,10,12,10,8,11}. Найдем ДКТ, ДСП и ДПХ этого множества. Проведем следующий эксперимент - отквантуем полученные результаты с точностью до десятков, а для синус преобразования, даже вдвое точнее.
dct={30,0,0,0,0,0,0,0}- черний цвет,
dst={0,25,0,10,0,10,0,10}- красный цвет,
dht={80,0,10,0,0,0,10,0}- зеленый цвет.
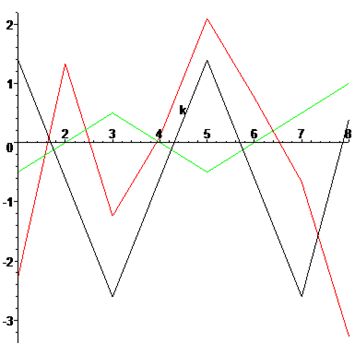
Ошибка восстановления данных по отквантованным частотным коэффициентам.
Полученные результаты говорят о перспективности преобразования Хартли. Для того, чтобы проверить и убедиться в эффективности дискретного преобразования Хартли перед косинус - и синус-преобразованием, построим нормы частотных доменов, полученных с использованием соответствующих преобразований.
Используя идеологию JPEG, разобьем изображение на квадраты со стороной в восемь пикселов и на каждом квадрате вычислим соответствующие частотные коэффициенты. Для ДКП это \[ c^k_{i,j}=\frac{1}{4}C_iC_j\sum_{x=0}^7\sum_{y=0}^7p_{x,y}\cos\frac{(2x+1)i\pi}{16}\cos\frac{(2y+1)j\pi}{16}, \] где \[ C_i=\left\{ \begin{array}{ll} \frac{1}{\sqrt{2}}, &i=0;\\ 1, &i\gt 0. \end{array} \right. \] для ДСП \[ s^k_{i,j}=\frac{1}{4}C_iC_j\sum_{x=0}^7\sum_{y=0}^7p_{x,y}\sin\frac{(2x+1)i\pi}{16}\sin\frac{(2y+1)j\pi}{16}, \] и для ДПХ \[ h^k_{i,j}=\sum_{x=0}^7\sum_{y=0}^7p_{x,y}\mathrm{cas }\frac{2xi\pi}{16}\mathrm{cas }\frac{2yj\pi}{16}, \] где k - номер квадрата.
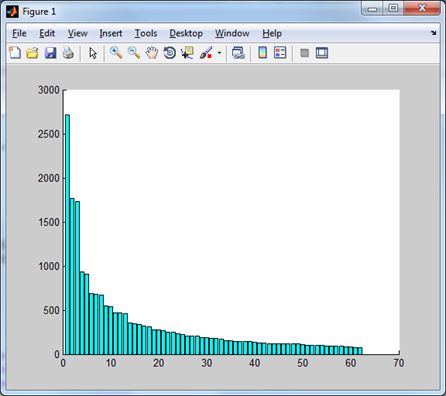
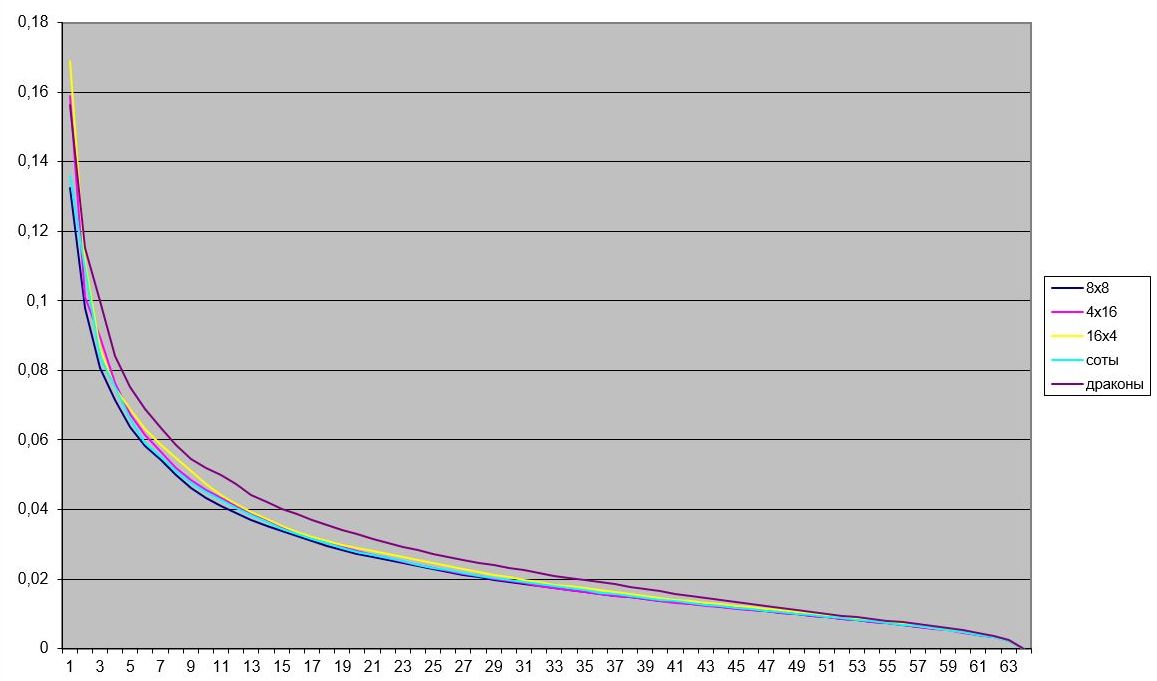
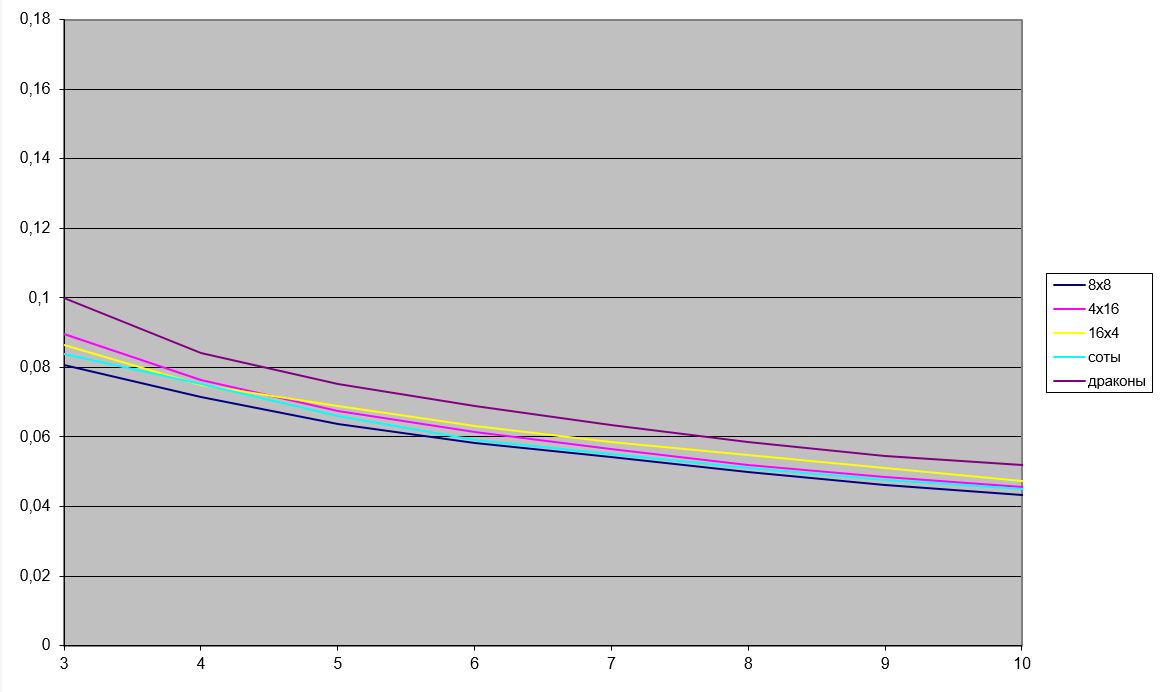
Множество соответствующих частотных коэффициентов \(D (q_{i, j}) \left \{q^k_{i, j}| k = 0,1, ... \right \}\) будем называть частотным доменом. Норма частотного домена находится по правилу \(\| D (q_{i, j}) \| = \sqrt{\sum_k \left (q^k_{i, j} \right)^2} \). По сути, норма, это энергия, соответствующая коэффициентам соответствующего домена. Чем больше значение нормы, тем больше информации аккумулирует этот домен. Поэтому, об эффективности того или другого преобразования можно судить по тому, насколько быстро убывают нормы частотных доменов. Для тестового изображения Lena имеем следующие результаты
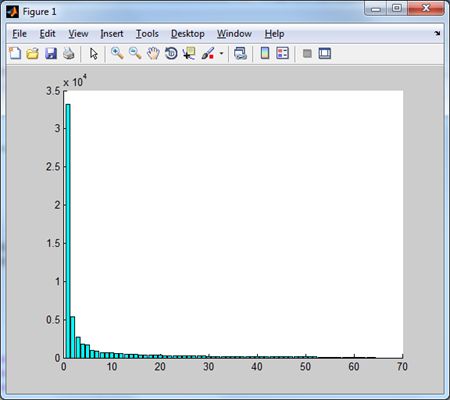 |  |
| Дискретное косинус-преобразования дает следующее распределение норм частотных доменов. |
Это же распределение, но без первого (низкочастотного) домена. |
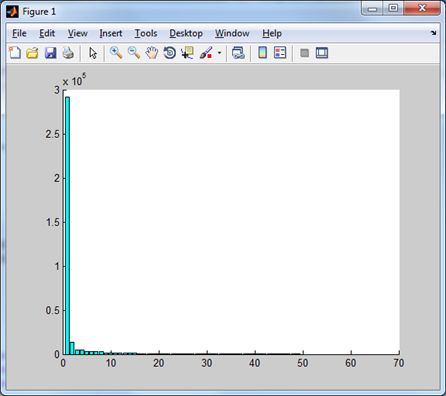 | 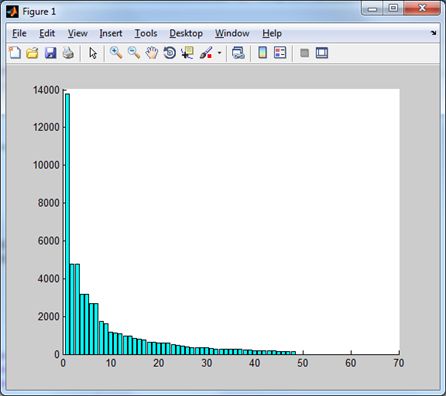 |
| Синус-преобразование дает следующее распределение. | И без низкочастотного домена. |
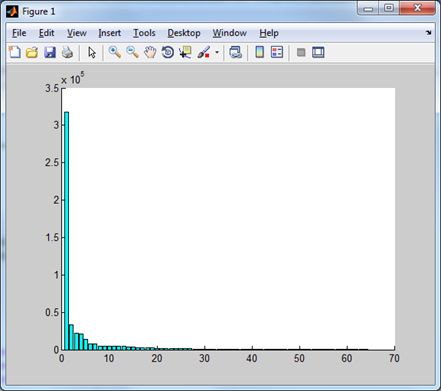 | 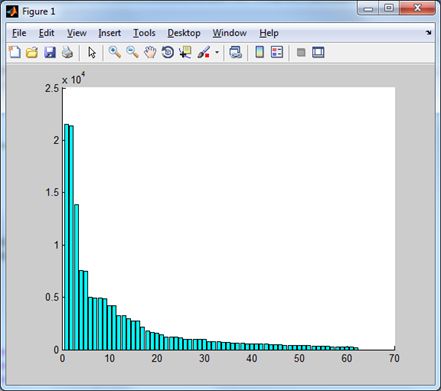 |
| Нормы доменов преобразования Хартли. | Эти же домены без низкочастотного. |
Коротко остановимся на методе сжатия изображений JPEG. Схематично метод JPEG заключается в следующем:
- Цветное изображение преобразуется из пространства смешивания цветов RGB в пространство YCrCb, где Y- люминесцентная составляющая (освещенность), Cr- компонента теплых оттенков и Cb- компонента холодных оттенков.
- На втором этапе происходит прореживания пикселей (при высоких степенях сжатия из четырех значений Cr и Cb берутся не все, два или даже одно значение).
- Группирование значений Y, Cr и Cb в блоки 8 × 8 с последующей фильтрацией, путем применения дискретного косинус-преобразования (ДКП).
- Квантование полученных коэффициентов, путем деления каждого коэффициента косинус-преобразования Фурье на специальное число (QC коэффициент квантования), с последующим округлением до целого. Именно на этом этапе идет невосполнимая потеря информации, за счет чего, собственно, и реализуется существенное сжатие изображения.
- Далее отквантованные значения упорядочиваются (согласно змейке JPEG) и сжимаются методом RLE (Run-lengthEncoding) - сжатие с использованием счетчиков нулей.
- И на последнем этапе применяется префиксный или энтропийный метод сжатия данных без потерь.

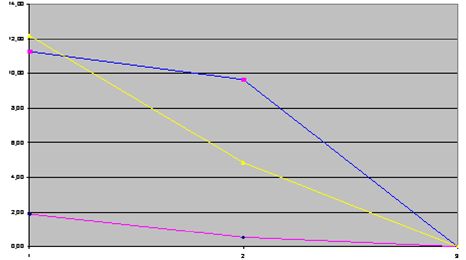
Ось абсцисс соответствует размеру файла, ось ординат - значение PSNR. Точки синего цвета соответствуют ДКП, пурпурного - ДПХ. Видно, что они образуют по два кластеры, которые соответствуют режимам сжатия. Кроме того, приведены две линейные аппроксимации, соединяющие средние значения каждого кластера. Данная иллюстрация показывает существенное улучшение качества сжатия изображения при использовании ДПХ вместо ДКП.
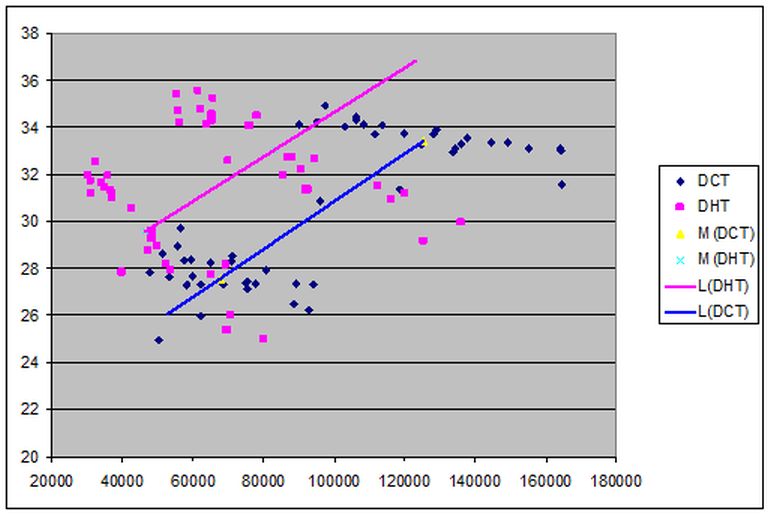
Очевидно, что \[ \sum_{i=0}^{N-1}p_i\mathrm{cas } \frac{2\pi\nu i}{N}=\sqrt{2}\sum_{i=0}^{N-1}p_i\cos \left(\frac{2\pi\nu i}{N}-\frac{\pi}{4}\right) \] то есть, преобразование Хартли представляет собой преобразование Фурье по косинусу с фазовым сдвигом π/4 и это дает неплохие результаты. Таким образом возникает вопрос, а существует преобразования по косинусу с любым углом фазового сдвига.
Одномерное дискретное тригонометрическое преобразования со свободным фазовым сдвигом.
Теорема. Пусть \(\varphi\in\left(0,\frac{\pi}{2}\right)\), тогда для всех \(\{h_m\}_{m=0}^{N-1}\) таких, что \(-\infty\lt h_m\lt \infty,m=0,1,...,N-1\) и \[ H_k=\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi mk}{N}-\varphi\right) \] имеет место равенство \[ h_n=\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}H_k\sin\left(\frac{2\pi nk}{N}+\varphi\right). \]
Доказательство. Подставим во второе соотношение значение \(H_k \) из первого равенства, тогда получим \[ \frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}{\left(\sum_{m=0}^{N-1}{h_m\cos\left(\frac{2\pi m k}{N}-\varphi\right)}\right)\sin\left(\frac{2\pi n k}{N}+\varphi\right)}= \] \[ \frac{2}{N\sin(2\varphi)}\sum_{m=0}^{N-1}{h_m\sum_{k=0}^{N-1}{\cos\left(\frac{2\pi m k}{N}-\varphi\right)}\sin\left(\frac{2\pi n k}{N}+\varphi\right)}= \] \[ \frac{2}{N\sin(2\varphi)}\sum_{m=0}^{N-1}{h_m\sum_{k=0}^{N-1}{\left(\sin\left(\frac{2\pi k(n+m)}{N}\right)+\sin\left(\frac{2\pi k (n-m)}{N}+2\varphi\right)\right)}}. \] Заметим, что (см., например, [8] стр.82) \begin{equation} \label{1} \sum_{\nu=0}^{N-1}\sin(\alpha+\nu\beta)=\frac{1}{\sin\frac{\beta}{2}}\sin\left(\alpha+\frac{N-1}{2}\beta\right)\sin\frac{N\beta}{2}, \end{equation} Пусть, прежде всего, \(n + m \ne N \), тогда из (\ref{1}) получим, \[ \sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n+m)}{N}\right)= \frac{1}{\sin\left(\frac{2\pi (n+m)}{2N}\right)}\sin\left(\frac{2\pi(n+m)(N-1)}{2N}\right) \sin\left(\frac{2\pi(n+m)N}{2N}\right). \] Из условия \(n+m\ne N\) получаем \[ \sin\left(\frac{2\pi (n+m)}{N}\right)\ne 0, \] а, с другой стороны, \[ \sin\left(\frac{2\pi N}{2N}\right)=\sin(\pi(n+m))=0, \] то есть, для \(n+m\ne N\) \[ \sum_{k=0}^{N-1}{\sin\left(\frac{2\pi k(n+m)}{N}\right)}=0. \] Если же \(n+m= N\), тогда \[ \sum_{k=0}^{N-1}{\sin\left(\frac{2\pi k(n+m)}{N}\right)}= \sum_{k=0}^{N-1}{\sin\left(\frac{2\pi kN}{N}\right)}= \sum_{k=0}^{N-1}{\sin\left(2\pi k\right)}=0. \] Таким образом для всех \(n,m=0,1,\ldots,N-1\) \[ \sum_{k=0}^{N-1}{\sin\left(\frac{2\pi k(n+m)}{N}\right)}=0. \] Рассмотрим соотношение \[ \sum_{k=0}^{N-1}{\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)}. \] Используя равенство (\ref{1}), получаем \[ \sum_{k=0}^{N-1}{\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)}= \frac{1}{\sin\left(\frac{2\pi (n-m)}{2N}\right)}\sin\left(\frac{2\pi (n-m)(N-1)}{2N}+2\varphi\right)\sin\left(\frac{2\pi (n-m)N}{2N}\right). \] Далее, замечая, что так как \(n,m=0,1,\ldots,N-1\), то \(n-m\ne N\). Пусть, \(n\ne m\) , тогда получаем, что \[ \sin\left(\frac{\pi (n-m)}{N}\right)\ne 0, \] но при этом \[ \sin\left(\frac{2\pi (n-m)N}{2N}\right)=\sin(\pi(n-m))=0 \] для всех \(n,m=0,1,\ldots,N-1\) и для \(n\ne m\), в том числе. И, наконец, пусть \(n=m\), тогда \[ \sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)=\sum_{k=0}^{N-1}\sin(0+2\varphi)=N\sin(2\varphi). \] Таким образом, получаем \[ \sum_{k=0}^{N-1}\left(\sin\left(\frac{2\pi k(n+m)}{N}\right)+\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)\right)= \left\{ \begin{array}{ll} N\sin(2\varphi), &n=m; \\ 0, &n,m=0,1,\ldots,N-1,n\ne m. \end{array} \right. \] Откуда получаем соотношение \[ \frac{1}{N\sin(2\varphi)}\sum_{m=0}^{N-1}h_m\sum_{k=0}^{N-1}\left(\sin\left(\frac{2\pi k(n+m)}{N}\right)+\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)\right)= \left\{ \begin{array}{ll} h_n, &n=m; \\ 0, &n,m=0,1,\ldots,N-1,n\ne m. \end{array} \right. \] Что и завершает доказательство теоремы.Отметим, что если \(\varphi = \frac {\pi}{4} \), то мы получим дискретное преобразование Хартли (ДПХ), то есть ДПХ является частным случаем полученного ДТП.
Использование возможности использования фазового сдвига для улучшения восстановления данных позволяет, на основании полученного дискретного преобразования, строить адаптивные фильтры, подстраивая фильтр не только для входных данных, но и, например, для используемого метода квантования или природы шума, вносящего искажения в сигнал.
Двумерное дискретное тригонометрическое преобразование со свободным фазовым сдвигом.
Так как одним из популярных сфер использования дискретного косинус-преобразования является цифровая обработка двухмерных сигналов, то есть изображений, то для использования полученного дискретного тригонометрического преобразования в обработке изображений применим двухмерное преобразование:прямой ход \[ h_{i,j}=\frac{2}{N\sin(2\varphi)}\sum_{n=0}^{N-1}\sum_{m=0}^{N-1}p_{n,m}\cos\left(\frac{2\pi ni}{N}-\varphi\right)\cos\left(\frac{2\pi mj}{N}-\psi\right), \] и обратный ход \[ p_{n,m}=\frac{2}{N\sin(2\psi)}\sum_{i=0}^{N-1}\sum_{j=0}^{N-1}h_{i,j}\sin\left(\frac{2\pi ni}{N}+\psi\right)\sin\left(\frac{2\pi mj}{N}+\varphi\right). \]
Используя это преобразование для блока 8 × 8 пикселей, можно получить лучший результат чем дискретное косинус-преобразования, но для получения такого результата необходимо выбрать соответствующие фазовые сдвиги. Этим дискретным тригонометрическим преобразованием можно заменить дискретное косинус-преобразования в стандарте JPEG без изменения логики кодирования и квантования, только заменив преобразования.Определение лучшего фазового сдвига.
Для определения наилучшего фазового сдвига, состоящего для двухмерного сигнала, из двух параметров \(\varphi \) и \(\psi \), предложен следующий подход:- Нужно вычислить значение Peak Signal to Noise Ration (PSNR) для восстановленного изображения, при почти крайних значениях сдвигов, например \(\varphi_1 = \pi / 100, \varphi_2 = \pi / 8 \) и \(\varphi_3 = \pi / 4 \), значение \(\psi \) лучше взять среднее, то есть \(\pi / 8 \).
- Найти точку максимума параболы проведенной через точки A (PSNR 1 ; φ 1 ), B (PSNR 2 ; φ 2 ) и C (PSNR 3 ; φ 3 ).
- Координата X найденной точки будет аппроксимацией искомого значения φ.
- Перейти к шагу 1 и провести эту же операцию для ψ используя найденное значение φ, данную операцию можно повторять несколько раз, используя поочередно φ и ψ, но практика показала, что и одного раза достаточно.
Для тестирования были взяты тестовые изображения из базы данных изображений TID2008 фирмы Kodak. Для каждого изображения были определены лучшие значения сдвигов, а также построены графики каждого значения PSNR в зависимости от фазовых сдвигов
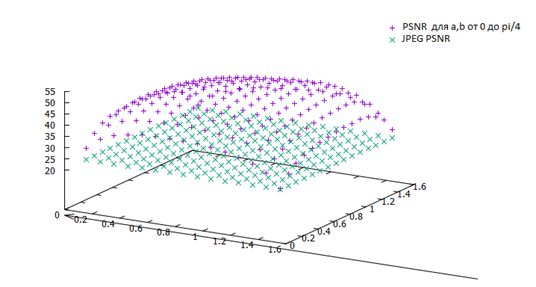
Распределение значений PSNR для различных значений φ и ψ на портретном изображении.
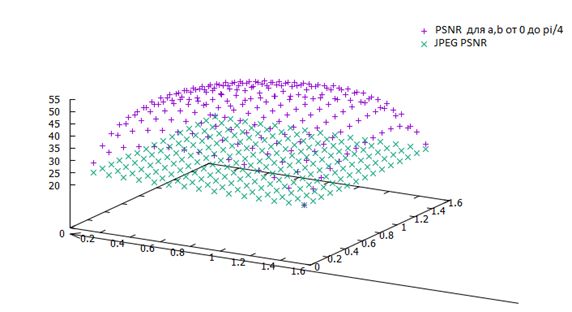
Распределение значений PSNR для различных значений φ и ψ на пейзажном изображении.
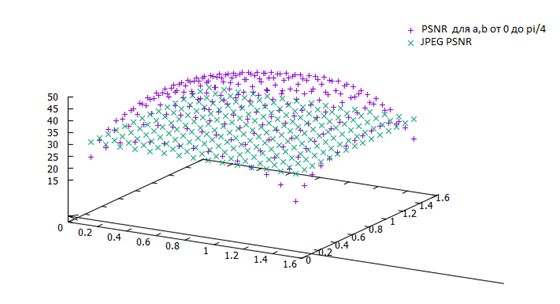
Распределение значений PSNR для различных значений φ и ψ на синтетическом изображении.
Рассмотрим следующую задачу: как выбрать базисные векторы, чтобы минимальным числом базисных векторов можно было наилучшим образом приблизить данные из некоторого набора.
Решению этой задачи отвечает метод главных компонент - ортогональное линейное преобразование базиса, при котором первый вектор нового базиса соответствует направлению максимальной
дисперсии данных, второй вектор - в следующем направлении максимальной дисперсии и так далее.
Метод главных компонент.
Метод главных компонент (МГК) - один из основных способов сокращения размерности данных с уменьшением количества информации, разработанный Карлом Пирсоном (Karl Pearson) в 1901 году. Используется во многих областях, таких как распознавание образов, компьютерное зрение, сжатие данных и др. (Более подробно с МГК можно ознакомиться, если перейти по ссылке). Нахождение главных компонент сводится к вычислению собственных векторов и значений ковариационной матрицы входных данных.Перейдем к рассмотрению метода МГК (PCA - Principal Component Analysis). Сначала проведем центрирование данных, для чего найдем константу μ, которая наилучшим образом описывает входные данные \[ \varepsilon \left( \mu \right) = \sum\limits_{i = 1}^n {\left( {x_i - \mu } \right)^2 \to \mathop {\min }\limits_\mu } . \] Для нахождения минимума найдем производную и приравняем ее к нулю, после чего найдем значение μ, которое дает минимум \[ \frac{d}{d\mu }\varepsilon \left( \mu \right) = - 2\sum\limits_{i = 1}^n {\left( {x_i - \mu } \right) = 0 \Rightarrow } \sum\limits_{i = 1}^n {\mu = } \sum\limits_{i = 1}^n {x_i \Rightarrow } \mu n = \sum\limits_{i = 1}^n {x_i \Rightarrow } \mu = \frac{1}{n}\sum\limits_{i = 1}^n {x_i } . \] Далее проведем центрирование данных, то есть, переопределим входные значения \(x_{new} = x_{old} - \mu \), вычитая из каждого полученное значение μ. Ясно, что новые данные имеют математическое ожидание, равное нулю \[ E\left( {X - E\left( X \right)} \right) = E\left( X \right) - E\left( X\right) = 0. \] Таким образом, мы сделали параллельный сдвиг в существующий системе координат.
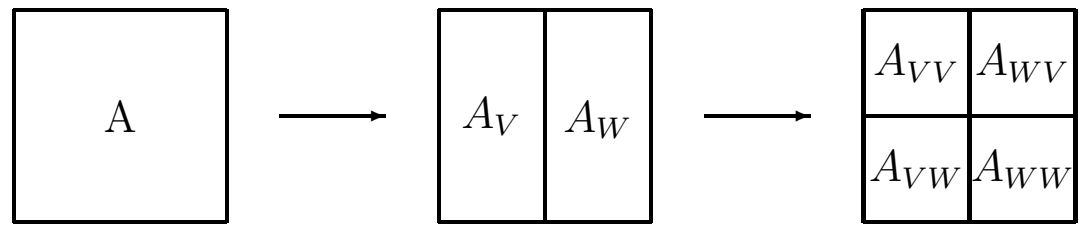
В дальнейшем будем считать, что наши данные центрированы и мы хотим найти наиболее точное представление данных \(D = \left\{ {x_1 ,...,x_n } \right\}\) в некотором подпространстве W с размерностью \(k \lt n \).
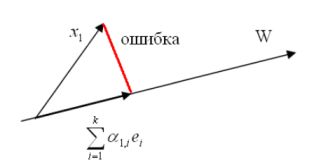
Пусть \(\left \{ {e_1 ..., e_k} \right \} \) ортогональный базис W . Произвольный вектор из W может быть записан в виде линейной комбинации векторов базиса, то есть, \(x_1 \) можно поставить в соответствие некоторый вектор \(\sum \limits_{i = 1}^k {\alpha_{1, i}} e_i \) из W . Погрешность между ними находится следующим образом \[ \varepsilon_1 = \left\| {x_1 - \sum\limits_{i = 1}^k {\alpha_{1,i} } e_i } \right\|_2^2 = \left\langle {x_1 - \sum\limits_{i = 1}^k {\alpha_{1,i} } e_i ,x_1 - \sum\limits_{i = 1}^k {\alpha_{1,i} } e_i } \right\rangle . \] Иллюстрация погрешности восстановления вектора.
Вначале упростим соотношение (\ref{2.1}) \[ \varepsilon \left( {e_1 ,...,e_k ,\alpha_{1,1} ,...,\alpha_{n,k} } \right) = \sum\limits_{j = 1}^n {\left\| {x_j - \sum\limits_{i = 1}^k {\alpha_{j,i} } e_i } \right\|_2^2 = }\] \[= \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - 2\sum\limits_{j = 1}^n {x_j^T \sum\limits_{i = 1}^k {\alpha_{j,i} } e_i + \sum\limits_{j = 1}^n {\sum\limits_{i = 1}^k {\alpha_{j,i}^2 } = } } } \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - 2\sum\limits_{j = 1}^n {\sum\limits_{i = 1}^k {\alpha_{j,i} x_j^T } e_i + \sum\limits_{j = 1}^n {\sum\limits_{i = 1}^k {\alpha_{j,i}^2 } .} } } \] Тогда \[ \frac{\partial }{\partial \alpha_{m,\ell} }\varepsilon \left( {e_1 ,...,e_k,\alpha_{1,1} ,...,\alpha_{n,k} } \right) = - 2x_m^T e_\ell + 2\alpha_{m,\ell}. \] Необходимое и достаточное условие экстремума будет иметь вид \[ - 2x_m^T e_\ell + 2\alpha_{m,\ell} = 0 \Rightarrow \alpha_{m,\ell} = x_m^T e_\ell . \] Таким образом, погрешность (\ref{2.1}) будет иметь вид \[ \varepsilon \left( {e_1 ,...,e_k } \right) = \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - 2\sum\limits_{j = 1}^n {\sum\limits_{i = 1}^k {\left( {x_j^T e_i } \right)x_j^T } e_i + \sum\limits_{j = 1}^n {\sum\limits_{i = 1}^k {\left( {x_j^T e_i } \right)^2} .} } } \] Проводя упрощения, имеем \begin{equation} \label{2.2} \varepsilon \left( {e_1 ,...,e_k } \right) = \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - \sum\limits_{j = 1}^n {\sum\limits_{i = 1}^k {\left( {x_j^T e_i } \right)^2} .} } \end{equation} Учитывая, что \(\left\langle {a,b} \right\rangle = a^Tb\) и \(\left\langle {b,a} \right\rangle = \left\langle {a,b} \right\rangle \), получаем \[ \left( {a^Tb} \right)^2 = \left( {a^Tb} \right)\left( {a^Tb} \right) = \left( {b^Ta} \right)\left( {a^Tb} \right) = b^T\left( {aa^T} \right)b, \] то есть, \[ \varepsilon \left( {e_1 ,...,e_k } \right) = \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - \sum\limits_{i = 1}^k {e_i^T \left( {\sum\limits_{j = 1}^n {\left( {x_j x_j^T } \right)} } \right)e_i } } = \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - \sum\limits_{i = 1}^k {e_i^T Se_i } } , \] где \(S = \sum\limits_{j = 1}^n {\left( {x_j x_j^T } \right)}\) ковариационная матрица.
Следующим шагом будет минимизация \[\varepsilon \left( {e_1 ,...,e_k } \right) = \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - \sum\limits_{i = 1}^k {e_i^T Se_i } }\] при условии \(e_i^T e_i = 1 \) для всех i . Для решения этой задачи будем использовать метод неопределенных множителей Лагранжа (Lagrange). Введем множители \(\lambda_1 ,...,\lambda_k\), отмечая, что \(\sum\limits_{j =1}^n {\left\| {x_j } \right\|_2^2 } \equiv Const\) и выпишем функцию цели \[ L\left( {e_1 ,...,e_k } \right) = \sum\limits_{i = 1}^k {e_i^T Se_i } - \sum\limits_{i = 1}^k {\lambda_i \left( {e_i^T e_i - 1} \right)} . \] Замечая, что \(\frac{d}{dX}\left( {X^TX} \right) = \frac{d}{dX}\left\langle {X,X} \right\rangle = 2X\) и если A симметричная матрица, то \(\frac{d}{dX}\left( {X^TAX} \right) = 2AX\), имеем, \[ \frac{\partial }{\partial e_m }L \left( {e_1 ,...,e_k } \right) = 2Se_m - 2\lambda_m e_m = 0, \] то есть, \(Se_m = \lambda_m e_m\). Таким образом, необходимо найти решение уравнения \(\left( {S - \lambda I} \right)e = 0\) (где I единичная матрица), что эквивалентно тому, что \(\lambda_m \) и \(e_m\) есть собственные значения и собственные векторы ковариационной матрицы S.
При этом погрешность имеет вид \begin{equation}\label{2.3} \varepsilon \left( {e_1 ,...,e_k } \right) = \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - \sum\limits_{i = 1}^k {\lambda_i\left\| {e_i } \right\|_2^2 } } = \sum\limits_{j = 1}^n {\left\| {x_j } \right\|_2^2 - \sum\limits_{i = 1}^k {\lambda_i} } . \end{equation} Минимизация (\ref{2.3}) состоит в выборе базиса W из k собственных векторов матрицы S , которые соответствуют k крупнейшим собственным значениям. Большее собственное значение S дает большую вариацию в направлении соответствующего собственного вектора. Этот результат можно переформулировать следующим образом - проекция X на подпространство размера k , которая обеспечивает наибольшую вариацию. Таким образом МГК может трактоваться следующим образом - берем ортогональный базис и вращаем его пока на одном из направлений не получим максимальную вариацию. Фиксируем это направление и вращаем другие, пока не найдем второе направление и так далее.
Пусть \(\left \{ {e_1 ..., e_n} \right \} \) все собственные векторы матрицы S , отсортированные в порядке уменьшения соответствующего собственного значения, тогда для произвольного \[ x_i = \sum\limits_{j = 1}^n {\alpha_{i,j} } e_j = \underbrace {\alpha _{i,1} e_1 + ... + \alpha_{i,k} e_k }_{approximation} + \overbrace {\alpha _{i,k + 1} e_{k + 1} + ... + \alpha_{i,n} e_n }^{error} \]
коэффициенты \(\alpha_{m, \ell} = x_m^T e_\ell \) являются координатами главных компонент, и чем больше значение k , тем лучшую аппроксимацию получаем. Приведем алгоритмизацию МГК.
Пусть \(D = \left \{ {x_1^0, ..., x_n^0} \right \} \) входные (оригинальные) данные, каждый из этих векторов \(x_i^0 \) имеет размер N
- Найдем среднее \(\mu = \frac{1}{n} \sum \limits_{i = 1}^n {x_i^0} \).
- Вычтем среднее по каждому вектору \(x_i = x_i^0 - \mu \).
- Найдем ковариационную матрицу \(S = \sum \limits_{j = 1}^n {x_jx_j^T} \).
- Вычислим собственные векторы \(\left \{ {e_1 ..., e_k} \right \} \), которые соответствуют k самым большим собственным значениям S.
- Пусть \(\left \{ {e_1 ..., e_k} \right \} \) составляют матрицу \(E = \left [{e_1 ... e_k} \right] \).
- Тогда ближе всего к x лежит \(z^TE + \mu \).
Итерационный алгоритм вычисления главных компонент.
Описанный метод получения главных компонент достаточно ресурсоемок и нестабильный, особенно в случае, если собственные значения матрицы близки к нулю.Поэтому более эффективным является использование итерационного метода нахождения главных компонент. Для этого рассмотрим задачу (\ref{2.1}) с другой точки зрения.
В случае i = 1 задача (\ref{2.1}) сводится к нахождению одной компоненты \(e_1 \), которая наилучшим образом восстанавливает все исходные данные \(\left \{ {x_1, ... , x_n} \right \} \). \begin{equation} \label{2.4} \varepsilon \left( {e_1 ,\alpha_{1,1} ,...,\alpha_{n,1} } \right) = \sum\limits_{j = 1}^n {\left\| {x_j - \alpha_{j,1} e_1 } \right\|_2^2 } \to \min \end{equation} по всем \(e_1 \) i \(\left\{ {\alpha_{i,1} } \right\}_{i = 1}^n \) при условии \(\sum\limits_{i = 1}^n {\alpha_{i,1}^2 = 1.} \)
Если \(\left\{ {\tilde{\alpha }_{i,1} } \right\}_{i = 1}^n \) и \(\tilde{e}_1\) есть решение этой задачи, то \(\Delta x_j = x_j - \tilde {\alpha }_{j,1}\tilde {e}_1 \) - погрешность восстановления данных одной первой главной компонентой, тогда, решая задачу \[ \sum\limits_{j = 1}^n {\left\| {\Delta x_j - \alpha_{j,2} e_2 } \right\|_2^2 } \to \min \] по всем \(e_2\) та \(\left\{ {\alpha_{i,2} } \right\}_{i = 1}^n \) при условии \(\sum\limits_{i = 1}^n {\alpha_{i,1}^2 = 1} \), получаем вторую главную компоненту \(\tilde {e}_2 \) и соответствующий вектор \(\left\{ {\tilde {\alpha }_{i,2} } \right\}_{i = 1}^n \) и т.д.
При фиксованных \(\left\{ {\alpha_{i,1} } \right\}_{i = 1}^n \) задача (\ref{2.4}) решается методом наименьших квадратов. В силу того, что функцией цели является квадратичный функционал, необходимое и достаточное условие экстремума совпадают. Таким образом, решение задачи сводится к поиску решения уравнения \[ \frac{\partial }{\partial e_1 }\varepsilon \left( {e_1 ,\alpha_{1,1} ,...,\alpha_{n,1} } \right) = - 2\sum\limits_{j = 1}^n {\left( {x_j - \alpha_{j,1} e_1 } \right)\alpha_{j,1} } = - 2\left( {\sum\limits_{j =1}^n {x_j \alpha_{j,1} } - \sum\limits_{j = 1}^n {\alpha_{j,1}^2 e_1 } } \right). \] Отсюда имеем \[ \frac{\partial }{\partial e_1 }\varepsilon \left( {e_1 ,\alpha_{1,1} ,...,\alpha_{n,1} } \right) = - 2\sum\limits_{j = 1}^n {\left( {x_j - \alpha_{j,1} e_1 } \right)\alpha_{j,1} } = - 2\left( {\sum\limits_{j =1}^n {x_j \alpha_{j,1} } - \sum\limits_{j = 1}^n {\alpha_{j,1}^2 e_1 } } \right). \] учитывая условие нормирования единицей, то есть \(\sum\limits_{i = 1}^n {\alpha_{i,1}^2 = 1}\), имеем \[ e_1 = \sum\limits_{j = 1}^n {x_j \alpha_{j,1} } . \] Следующий шаг будем делать из условия, что в задаче (\ref{2.4}) нам известна компонента \(e_1 \) и требуется найти экстремум по \(\left\{ {\alpha_{i,1} } \right\}_{i = 1}^n\) \[ \frac{\partial }{\partial \alpha_{\nu ,1} }\varepsilon \left( {e_1 ,\alpha_{1,1} ,...,\alpha_{n,1} } \right) = - 2\left( {x_\nu - \alpha_{\nu ,1} e_1 } \right)e_1 = - 2\left( {\left\langle {x_\nu ,e_1 } \right\rangle - \alpha_{\nu ,1} \left\langle {e_1 ,e_1 } \right\rangle } \right) = 0, \] то есть \[ \alpha_{\nu ,1} = \frac{\left\langle {x_\nu ,e_1 } \right\rangle }{\left\langle {e_1 ,e_1 } \right\rangle }, \] где, как обычно, \(\left\langle {x,y} \right\rangle\)- скалярное произведение векторов x и y.
Далее, считая найденные \(\left\{ {\alpha_{i,1} } \right\}_{i = 1}^n \) уже известными, повторяем весь процесс, пока не достигнем стабилизации погрешности.
Полученные \(e_1 \) будем считать первой главной компонентой \(\tilde {e}_1 \). Тогда \(\Delta x_j = x_j - \tilde {\alpha }_{j,1} \tilde {e}_1\) - погрешность восстановления данных одной первой главной компонентой.
Применяя этот метод к погрешности восстановления \(\Delta x_j \), находим вторую главную компоненту \(e_2 \) вместе с коэффициентами \(\alpha_{j, 2} \), и так далее.
Приведем алгоритмизацию этого алгоритма.
Во-первых центрируем данные, вычитая из входных данных среднее значение и в дальнейшем считаем, что данные в среднем равны нулю.
- Пусть номер итерации ν = 1.
- Выбираем стартовые значения \(\left \{ {\alpha_{i, 1}^\nu} \right\}_{i = 1}^n \), например, пусть все они между собой равны, то есть \(\alpha_{i, 1}^\nu = \frac{1}{\sqrt n}, i = 1,2, ..., n \).
- Вычислим \(e_1^\nu = \sum \limits_{j = 1}^n {x_j \alpha_{j, 1}^\nu} \).
- Далее найдем \(\beta_i = \frac {\left \langle {x_i, e_1^\nu} \right \rangle} {\left \langle {e_1^\nu, e_1^\nu} \right \rangle} \) и, после нормирования единицей, имеем \[ \alpha_{i,1}^{\nu + 1} = \frac{\beta_i }{\sqrt {\sum\limits_{j = 1}^n {\beta_j^2 } } }. \]
- Пусть ν = ν+ 1.
- Проведем проверку критерия остановки, в качестве которого может быть либо стабилизация коэффициентов \(\left\{ {\alpha_{i,1}^\nu } \right\}_{i = 1}^n\), либо стабилизация главной компоненты \(e_1^\nu \) или проверка на заданное фиксированное число итераций. Если условие остановки итерационного процесса не выполнено, то переходим к пункту 3.
Переход от модели RGB к оптимальной трехкомпонентной модели.
Перейдем к использованию метода главных компонент в компьютерной графике. Здесь важную роль играет конвертация изображения из пространства равноправных цветных характеристик в пространство неравноправных (см. раздел "Свет и цвет"). Произвольное изображение визуализируется с использованием смешивания равноправных цветных компонент - красной, зеленой и синей составляющих - модель RGB. В качестве неравноправных цветных компонент, как правило, используют, соответственно, также три компонента - значение освещенности (люминесцентную составляющую), характеристику теплых тонов и характеристику холодных тонов. Использование неравноправных цветных компонент используют для сжатия изображений и видео-потоков, применяя к каждой из неравноправных компонент свой метод сжатия.Можно подходить к проблеме построения неравноправного цветового пространства с другой точки зрения, исходя из максимальной информативности каждой компоненты. Применим метод главных компонент для получения неравноправной трехкомпонентной модели оптимальной с точки зрения минимизации среднеквадратичной погрешности восстановления данного изображения. Таким образом, первая из полученных цветных компонент будет нести наибольшую информацию относительно изображения между всех полученных цветных компонент, а вторая будет иметь наибольшую информацию среди тех, кто остались.
Таким образом, в нашей терминологии, задача (\ref{2.1}) будет иметь вид \[ \left\| {R - \sum\limits_{i = 1}^3 {\alpha_{r,i} } e_i } \right\|_2^2 + \left\| {G - \sum\limits_{i = 1}^3 {\alpha_{g,i} } e_i } \right\|_2^2 + \left\| {B - \sum\limits_{i = 1}^3 {\alpha_{b,i} } e_i } \right\|_2^2 \to \min , \] где минимум берется по всем \(\alpha_{r, i} \alpha_{g, i} \alpha_{b, i} \) и \(e_i \quad i = 1,2,3. \) В качестве данных рассмотрим тестовое изображение Lena. Применяя метод главных компонент, имеем \[ \left( { {\begin{array}{*{20}c} R \hfill \\G \hfill \\B \hfill \\ \end{array} }} \right) = \left( {\begin{array}{l} \mbox{ 0.767785 0.45439 0.4517034} \\ \mbox{ - 0.6164395 0.716085 0.3274513} \\ \mbox{ - 0.174667 - 0.5298553 0.8299064} \\ \end{array}} \right)\left( { {\begin{array}{*{20}c} {e_1 } \hfill \\ {e_2 } \hfill \\ {e_3 } \hfill \\ \end{array} }} \right). \] Здесь в первом столбце матрицы стоят коэффициенты \(\alpha_{r, 1}, \alpha_{r, 2}, \alpha_{r, 3} \), во втором - \(\alpha_{g, 1} , \alpha_{g, 2}, \alpha_{g, 3} \) и в третьем - \(\alpha_{b, 1}, \alpha_{b, 2}, \alpha_{b, 3} \). Тогда восстановления тестового изображения по одной компоненте можно записать в виде \[ R_{i,j}=\mbox{0.767785 }Y_{i,j} , \\ G_{i,j}=\mbox{ 0.45439} Y_{i,j}, \\ B_{i,j}=\mbox{0.4517034} Y_{i,j}, \] где \(Y_{i,j}\) – значение первой главной компоненты \(e_1 \), которые соответствуют пикселю с координатами (i, j) .

Изображение Lena, восстановленное по одной первой главной компоненте.
Оптимальный метод кодирования изображения.
В рассмотренном выше примере изображение было разложено на три оптимальных (с точки зрения энергии слоев) информационных домена (слоя). Обобщим данный подход используя для разбиения изображения на \(3 \times n^2 (n \ge 1) \) информационных доменов с возможностью динамической подгрузки (по аналогии с прогрессивным Jpeg). То есть, реализовать оптимальный метод прогрессивной развертки изображения на \(3 \times n^2 (n \ge 1) \) слоев.Суть метода состоит в следующем. Разобьем наше изображение размером \(H \times W \) на квадраты \(P_{x, y} \) размером \(n \times n (n \ge 1) \). Для простоты будем считать, что \(H = N \times n, W = M \times n \). Каждому пикселю \(p_{nx + i, ny + j} (i, j = 0,1, ..., n-1) \) данного квадрата соответствуют три цветные компоненты \(r{nx + i, ny + j}, g_{nx + i, ny + j}, b_{nx + i, ny + j} \) (красная, зеленая и синяя составляющие). То есть, общая информация на квадрате \(P_{x, y} \) описывается данным \[ (r_{nx+i,ny+j},g_{nx+i,ny+j},b_{nx+i,ny+j}),(r_{nx+i,ny+j},g_{nx+i,ny+j},b_{nx+i,ny+j}),...,(r_{nx+i,ny+j},g_{nx+i,ny+j},b_{nx+i,ny+j}). \] Сформируем домены входящей информации, например, следующим образом \[ X_0=\{r_{0,0},r_{n,0},...,r_{nx,ny},...,r_{H-n-1,W-n-1}\}, \] \[ X_1=\{g_{0,0},g_{n,0},...,g_{nx,ny},...,g_{H-n-1,W-n-1}\}, \] \[ X_2=\{b_{0,0},b_{n,0},...,b_{nx,ny},...,b_{H-n-1,W-n-1}\}, \] \[ X_3=\{r_{1,0},r_{n+1,0},...,r_{nx+1,ny},...,r_{H-n,W-n-1}\}, \] \[ X_4=\{g_{1,0},g_{n+1,0},...,g_{nx+1,ny},...,g_{H-n,W-n-1}\}, \] \[ X_5=\{b_{1,0},b_{n+1,0},...,b_{nx+1,ny},...,b_{H-n,W-n-1}\}, \] \[\ldots\] \[ X_{3\times n^2-2}=\{r_{n-1,n-1},r_{2n-1,2n-1},...,r_{(n+1)x-1,(n+1)y-1},...,r_{H,W}\}, \] \[ X_{3\times n^2-1}=\{g_{n-1,n-1},g_{2n-1,2n-1},...,g_{(n+1)x-1,(n+1)y-1},...,g_{H,W}\}, \] \[ X_{3\times n^2}=\{b_{n-1,n-1},b_{2n-1,2n-1},...,b_{(n+1)x-1,(n+1)y-1},...,b_{H,W}\}. \] Рассмотрим задачу \[ \sum_{j=0}^{3\times n^2}\left\|X_j-\sum_{i=0}^k\alpha_{j,i}Y_j\right\|^2_2\to\min, \] где минимум берется по всем \(\left\{Y_i\right\}_{i=0}^k, \alpha_{j,i}(i=0,1,\ldots,k,j=0,1,...,3\times n^2).\)
Как видно, для решения этой задачи можно использовать итерационный метод главных компонент, алгоритм которого приведен выше.
Таким образом, пусть мы получили все \(\left\{Y_i\right\}_{i=0}^k, \alpha_{j,i}(i=0,1,\ldots,k,j=0,1,...,3\times n^2).\) Опишем алгоритм прогрессивного восстановления исходных данных.
Понятное дело, что множество \(\left \{X_j \right \}_{j = 0}^{3 \times n^2} \) описывает все пиксели изображения, то есть, если \[X^0_j=\alpha_{j,0}Y_0,\] то \(\left\{X_j^0\right\}_{j=0}^{3\times n^2}\) является первой итерацией восстановления нашего изображения.

Изображение Lena, восстановлено по одной итерацией.

Изображение Lena, восстановленное по второй итерацией.
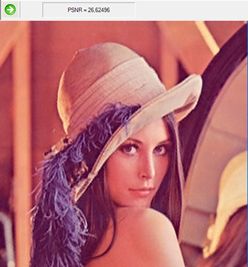
Изображение Lena на десятой итерации.
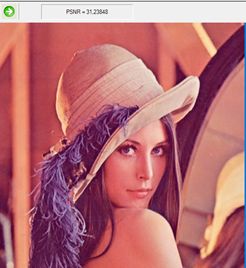
Изображение Lena на 21 из 192 итераций.
Приведем некоторые примеры.
Пусть задан любой двумерный паркет, покрывающий всю плоскость. Каждый элемент паркета состоит из n пикселей. Перенумеруем все пиксели элемента паркета произвольным, но фиксированным способом. Выбирая из каждого элемента паркета пиксель с одним и тем же номером, получим n компонент. Заметим, что результат оптимальной фильтрации не зависит от способа нумерации точек на элементе паркета.Для простейшего случая - квадратного паркета


Изображение Lena, собранные из одного квадратного домена.

Изображение Lena, собранные из семи квадратных доменов.
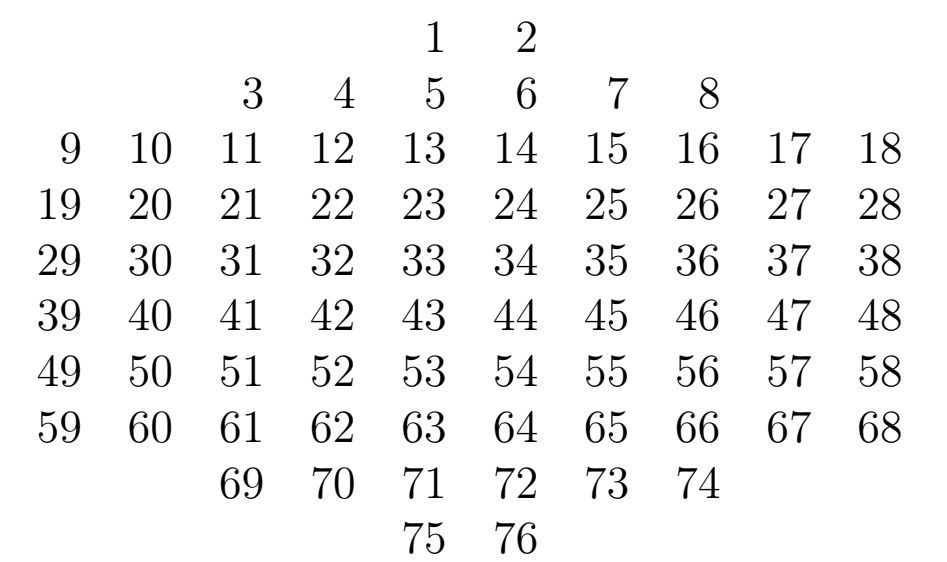

Изображение Lena, собранное из одного домена с шестиугольным паркетом.

Изображение Lena, собранные из семи доменов с шестиугольным паркетом.

Изображение Lena, собранное из одного домена с паркетом «Дракон».

Изображение Lena, собранное из четырех доменов с паркетом «Дракон».

Изображение Lena, собранные из семи доменов с паркетом «Дракон».
Вейвлеты в компьютерной графике.
Всплески (wavelets) появились в начале 1980-х годов на стыке теории функций, функционального анализа, обработки сигналов и изображений, квантовой теории поля. Развитие теории всплесков связано с именами А. Гроссмана, Ж. Морлета, Ж. Стремберга, Я. Мейера, С. Малла, И. Добеши и многих др. (Более подробно с вейвлетами можно ознакомиться, если перейти по ссылке)Подобно анализу Фурье теория всплесков находит применение в исследовании частотных характеристик функции f с помощью всплеск-преобразования. При описании функций с конечным носителем, сигналов, с переменными во времени частотами с помощью анализа Фурье, возникают трудности, которые объясняются свойствами тригонометрических функций на оси \(\mathbb{R} \). Например, преобразование Фурье функции f в случае δ-функции Дирака, которая имеет в качестве носителя единую точку, вырождается в функцию \(\hat{\delta} (\omega) = 1 \), распространенную на всю числовую ось. При обработке сигналов с переменными частотами традиционный анализ Фурье не позволяет выделить частоты, составляющие сигнал в окрестности произвольного момента времени. Аппарат всплесков позволяет автоматически осуществлять локализацию как по времени, так и в частотной области.
Приведем один алгоритм фильтрации векторного поля, то есть набора векторов одинаковой размерности.
Эти результаты являются основополагающими для всех алгоритмов, связанных с оптимальной фильтрацией фильтрами, подобными фильтрам Хаара и Уолша-Адамара одной и многих переменных.
В численном и функциональном анализе дискретные вейвлет-преобразования (ДВП) относятся к преобразованиям, в которых вейвлеты представлены дискретными сигналами (выборками).
Впервые ДВП было придумано венгерским математиком Альфредом Хааром. Для входного сигнала, представленного массивом 2 n чисел, вейвлет-преобразование Хаара просто группирует элементы по 2 и образует из них суммы и разности. Группировка сумм проводится рекурсивно для следующего уровня разложения. В итоге получается 2 n -1 разность и одна общая сумма.
Это простое ДВП иллюстрирует общие полезные свойства вейвлетов. Во-первых, преобразование можно выполнить используя \(n \log_2n \) операций. Во-вторых, оно не только раскладывает сигнал на некоторое подобие частотных полос (путем анализа его в разных масштабах), но и представляет временную область, то есть моменты возникновения тех или иных частот в сигнале.
Приведем определение и обозначение, необходимые нам в дальнейшем.
Множество векторов \(X^k=\left\{x_i^k\right\}(k = 0, .., n-1, i = 0,1, .., N-1)\) одинаковой розмерности N будем называть компонентами векторного поля или просто компонентами. Под фильтром \(H^\nu=\{h_i^\nu \} (\nu = 0, .., n-1)\) будем понимать вектор с n координатами.
Систему векторов \(H^\nu (\nu = 0, .., n-1)\) будем называть ортонормованной, если \[ H^\nu\bot H^\mu \Leftrightarrow \left\lt H^\nu,H^\mu \right\gt=0 \hbox{ и } \left\lt H^\nu,H^\nu \right\gt=1. \] Здесь <a, b> традиционное скалярное произведение векторов a и b.
Под фильтрацией компонентов \(X^k (k = 0, .., n-1)\) системой фильтров \(H^k (k = 0, .., n-1)\) будем понимать вычисления множества (частотного домена) по правилу \begin{equation}\label{w:1} Y^\nu=\sum_{k=0}^{n-1}h_\nu^k X^k. \end{equation} В координатной форме это соотношение будет иметь вид \[ y_i^\nu=\sum_{k=0}^{n-1}h_\nu^k x_i^k. \] Величину \begin{equation}\label{w:2} X_m^\nu=\sum_{k=0}^{m-1}h_\nu^k Y^k \end{equation} будем называть восстановлением компоненты \(X^\nu\) по m частотным доменам. Если m = n, то получаем восстановление компоненты по полному набору частотных доменов.
Первое соотношение называется декомпозицией, а последнее - реконструкцией данных.
В случае, если для данного массива \(F = \{f_i \} \) и для n = 4 компоненты определены правилом \[ X^0=\{x_i^0 \}=\{f_{4i} \},X^1=\{x_i^1 \}=\{f_{4i+1} \},\\ X^2=\{x_i^2 \}=\{f_{4i+2} \},X^3=\{x_i^3\}=\{f_{4i+3} \}, \] для фильтров Уолша-Адамара \[ H^0=0.5 \{1,1,1,1\},H^1=0.5 \{1,1,-1,-1\},\\ H^2=0.5\{1,-1,1,-1\},H^3=0.5\{1,-1,-1,1\} \] процедура декомпозиции (\ref{w:1}) будет иметь вид \[ y_i^0=0.5 (f_{4i}+f_{4i+1}+f_{4i+2}+f_{4i+3} ),\\ y_i^1=0.5(f_{4i}+f_{4i+1}-f_{4i+2}-f_{4i+3} ),\\ y_i^2=0.5 (f_{4i}-f_{4i+1}+f_{4i+2}-f_{4i+3} ),\\ y_i^3=0.5 (f_{4i}-f_{4i+1}-f_{4i+2}+f_{4i+3} ), \] а формулы реконструкции (\ref{w:2}), например, для m = 2 \[ f_{4i}=0.5 (y_i^0+y_i^1 ),\\ f_{4i+1}=0.5 (y_i^0+y_i^1 ),\\ f_{4i+2}= 0.5 (y_i^0-y_i^1 ),\\ f_{4i+3}=0.5(y_i^0-y_i^1 ). \] Полная реконструкция (то есть m = n ) определяется соотношениями \[ f_{4i}=\frac{1}{2} (y_i^0+y_i^1+y_i^2+y_i^3 ),\\ f_{4i+1}=\frac{1}{2}(y_i^0+y_i^1-y_i^2-y_i^3 ),\\ f_{4i+2}=\frac{1}{2}(y_i^0-y_i^1+y_i^2-y_i^3 ),\\ f_{4i+3}=\frac{1}{2}(y_i^0-y_i^1-y_i^2+y_i^3 ). \] Таким образом, задача использования фильтров разбивается на две. Первая из которых - сведение сигнала (в общем случае многокомпонентного и многоразмерного) к системе компонент одинаковой размерности. В частности, для фильтрации изображений это 3-компонентный двумерный сигнал, для видео - трехкомпонентный трехмерный и так далее. Вторая задача состоит в получении системы лучших (в том или ином смысле) фильтров для n компонент.
Фундаментальным понятием теории вейвлет есть понятие кратномасштабного анализа (КМА).
Кратномасштабный анализ в \(L^2 (\mathbb{R}^n) \) - это последовательность замкнутых подпространств \[ \ldots \subset V^{-1}\subset V^0 \subset V^1 \subset \] для которых выполняются условия
- \(\overline{\bigcup_{j\in Z}V^j}=L^2 (\mathbb{R}^n );\)
- \(\bigcap_{j\in Z}V^j=\{0\};\)
- \(f\in V^j \Leftrightarrow f\left(2^{-j\circ}\right)\in V^0;\)
- Найдется такая функция \(\varphi\in V^0\)(масштабирующая функция), множество ее сдвигов φ (x-n) создает ортогональный базис пространства \(V^0\).
Кроме того, из свойств КМА следует, что для любого \(j \in Z \) множество функций \(\varphi^j_k(x)=2^{j/2}\varphi(2^jx-k)\) \(k=0,\pm 1, \ldots\) создают ортогональный базис. Множитель \(2^{j / 2} \) является результатом того, что замена x на 2x уменьшает норму в \(2^{1/2} \) раз .
Так как \(V^0 \subset V^1 \), то функция φ является линейной комбинацией функций \(\{\varphi^1_n \} \). Таким образом, найдется множество коэффициентов \(\{h_n \} \) таких, что \begin{equation}\label{w.1} \varphi(x)=\sqrt{2}\sum_{n\in Z}h_n\varphi(2x-n), \end{equation} Из равенства Парсеваля имеем \(\sum_nh^2_n = 1. \)
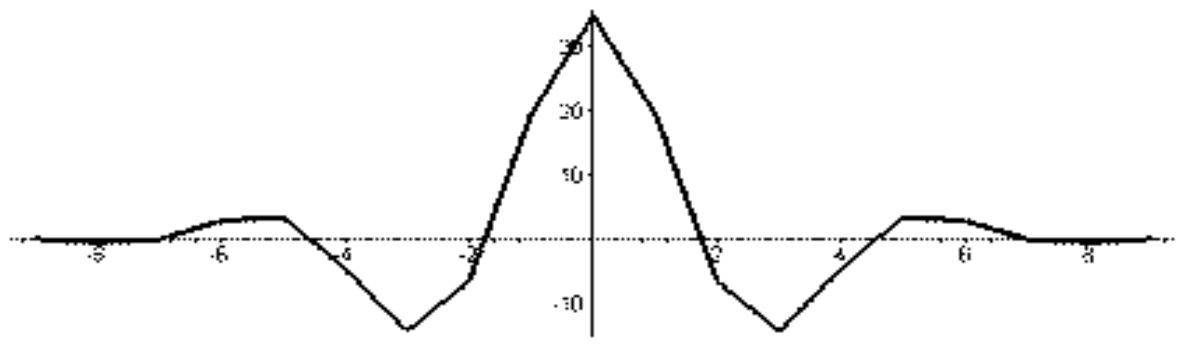
Функция φ (x) называется масштабирующей (скелинг) функцией, а функция \begin{equation}\label{w.2} \psi(x)=\sqrt{2}\sum_{n\in Z}(-1)^{1-n}h_{1-n}\varphi(2x-n), \end{equation} называется вейвлетом или всплеском.
Учитывая, что \(V^{- 1} \subset V^0 \), можно записать \(V^{- 1} \oplus W^{- 1} = V^0. \) В качестве всплеска, который определяет сдвиги базиса в пространствах \(W^j \) возьмем функцию ψ и положим \[ \psi_n^j (x)=2^{j/2} \psi (2^j x-n). \] В таком случае \[ \sum_{n\in Z}c_n^{-1}\varphi_n^{-1}(x)+ \sum_{n\in Z}d_n^{-1}\psi_n^{-1}(x)= \sum_{n\in Z}c_n^{0}\varphi_n^{0}(x). \] Отсюда, применяя операцию скалярного произведения, получаем \[ c^{-1}_k=\sum_{n\in Z}c_n^0\left\lt \varphi^0_n(x),\varphi^{-1}_k(x)\right>= \sum_{n\in Z}c_n^0\left\lt \varphi^0_n(x), \sum_{m\in Z}h_{m-2k}\varphi^{-1}_m(x)\right>= \sum_{n\in Z}c_n^0{h_{n-2k}}. \] и \[ d^{-1}_k= \sum_{n\in Z}c_n^0{g_{n-2k}}. \] где \(g_n=(-1)^{1-n} h_{1-n}\).
Ясно, что в общем случае \(V^j \oplus W^j=V^{j+1}\) и \[\sum_{n\in Z}c_n^{j}\varphi_n^{j}(x)+ \sum_{n\in Z}d_n^{j}\psi_n^{j}(x)= \sum_{n\in Z}c_n^{j+1}\varphi_n^{j+1}(x)\] и общие формулы декомпозиции \[ c^{j}_k= \sum_{n\in Z}c_n^{j+1}{h_{n-2k}}, \] и \[ d^{j}_k= \sum_{n\in Z}c_n^{j+1}{g_{n-2k}}. \] Обобщая выше сказанное, имеем разложение \(V^0 \) в ортогональную сумму \[ V^0=W^{-1}\oplus W^{-2}\oplus \ldots W^{-k}\oplus V^{-k} \] и формула реконструкции на каждом шаге будет иметь вид \[ c^{j+1}_k= \sum_{n\in Z}c_n^{j}h_{k-2n}+\sum_{n\in Z}d_n^{j}g_{k-2n}.\] Приведенный алгоритм называется каскадным.
Ортогональные вейвлеты.
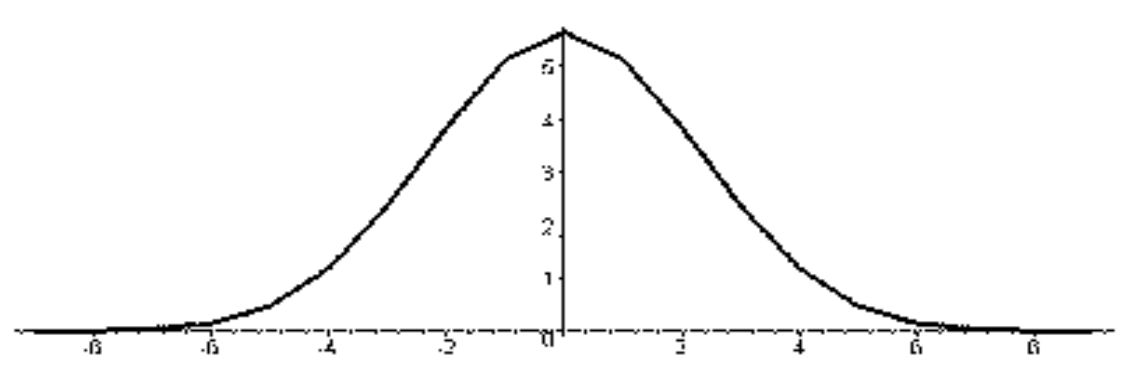
Пусть \(\varphi \) является ортогональной функцией на решетке с шагом 2, то есть \[ \left\lt \varphi,\varphi(\cdot-2k)\right>=\delta_{0,k} \] Или, что то же самое, \[ \sum_ih_ih_{i-2k}=\delta_{0,k}.\] Известен факт, что если ортогональная функция имеет компактный носитель, то этот носитель четный. Для простейшего случая он равен двум \[ h_0=\frac{1}{\sqrt{2}},h_1=\frac{1}{\sqrt{2}}. \] Соответствующая базовая функция называется функцией Хаара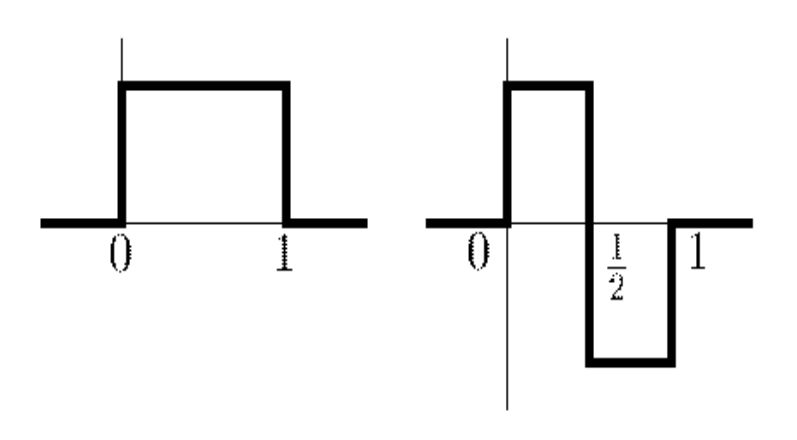
Из них наиболее информативным является низко-частотный домен, а наименее - высоко-частотный.
Применим данное преобразование (проведение декомпозиции) к тестовому изображению Lena и упорядочим следующим образом \[ \left[ \begin{array}{ll} C^{++} &C^{+-}\\ C^{\pm} &C^{--} \\ \end{array} \right]. \] После нормализации результат фильтрации будет выглядеть следующим образом





Среди всех ортогональных вейвлетов базис Хаара имеет худшие показатели.
Можно сравнить разложение константы методом ДКП (дискретное косинус-преобразования) и по Хаару
 |  |
Но самыми распространенными вейвлет-фильтрами являются биортогональные, которые используются в широком спектре разных задач, так или иначе связанных с частотным анализом сигналов. Относительно нашей темы, то надо отметить, что метод JPEG2000 основан на биортогональных вейвлетах.
Биортогональные преобразования являются обратимыми, но не обязательно ортогональным, что дает возможность получить дополнительные преимущества, так сделать вейвлет-фильтры симметричными, в отличие от ортогональных, которые сделать симметричными невозможно.
Пара масштабируемых функций \[ \varphi^{(0)}(x)=\sqrt{2}\sum_{n\in Z}h^{(0)}_n\varphi^{(0)}(2x-n), \] \[ \varphi^{(1)}(x)=\sqrt{2}\sum_{n\in Z}h^{(1)}_n\varphi^{(1)}(2x-n), \] вместе с соответствующей парой вейвлетов \[ \psi^{(0)}(x)=\sqrt{2}\sum_{n\in Z}g^{(0)}_n\varphi^{(0)}(2x-n), \] \[ \psi^{(1)}(x)=\sqrt{2}\sum_{n\in Z}g^{(1)}_n\varphi^{(1)}(2x-n), \] где \(g_n^{(m)}=(-1)^{1-n} h_{1-n}^{(m)},m=0,1,\) называется биортогональной, если \[ \left\lt \varphi^{(m)}\varphi^{(m)}(\circ -2k)\right\gt=\delta_{0,k},(m,n=0,1;n\ne m;k=0,\pm 1,…), \] тогда имеет место реконструкция сигнала \[ c^{j+1}_k=\sum_{n\in Z}c^j_nh^{(1)}_{k-2n}+\sum_{n\in Z}d^j_ng^{(0)}_{k-2n} \] где формулы декомпозиции такие \[ c^j_k=\sum_{n\in Z}c^{j+1}_nh^{(0)}_{k-2n}, d^j_k=\sum_{n\in Z}c^{j+1}_ng^{(1)}_{k-2n}. \] Как в ортогональном случае наиболее простыми являются фильтры Хаара, так для биортогональных, самый простой вариант дают фильтры 1-3, которые имеют следующий вид \[ h_0^{(0)}=1, h_0^{(1)}=1, h_{\pm 1}^{(1)}=\frac{1}{2}. \] В таком случае декомпозиция сигнала выглядит следующим образом \[ с_k^j=с_{2k}^{j+1}, d_k^j=-\frac{1}{2}c_{2k}^{j+1}+с_{2k+1}^{j+1}-\frac{1}{2} с_{2k+2}^{j+1}, \] а реконструкция \[ с_{2k}^{j+1}=с_k^j, с_{2k+1}^{j+1}=d_k^j+\frac{1}{2} с_k^j+\frac{1}{2} с_{k+1}^j. \] Приведем расчет классической биортогональной пары 3-5 Коэна-Добеши- Фово.
Пусть n = 1 и выпишем условие точности на константе, тогда \[ h_0^{(0)}=\frac{1}{\sqrt{2}}, h_{\pm 1}^{(0)}=\frac{1}{2\sqrt{2}}, \] а для n=2 \[ h_0^{(1)}+2h_{\pm 2}^{(1)}=\frac{1}{\sqrt{2}}, h_{\pm 1}^{(1)}=\frac{1}{2\sqrt{2}}, \] и условие биортогональности имеет вид \[ \frac{1}{8}+\frac{\sqrt{2}}{2}h^{(1)}_{\pm 2}=0, \frac{3}{4}-\sqrt{2}h^{(1)}_{\pm 2}=1. \] Отсюда сразу получаем биортогональную пару \[ h_0^{(0)}=\frac{\sqrt{2}}{2}, h^{(0)}_{\pm 1}=\frac{\sqrt{2}}{4},\\ h_0^{(1)}=\frac{3\sqrt{2}}{4}, h^{(1)}_{\pm 1}=\frac{\sqrt{2}}{4}, h^{(1)}_{\pm 2}=-\frac{\sqrt{2}}{8}. \]
Базисные функции биортогональной пары 3-5.
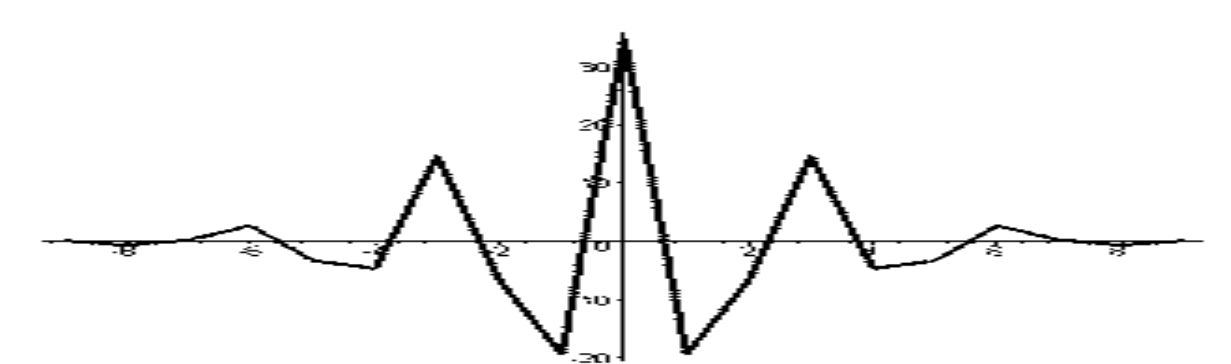
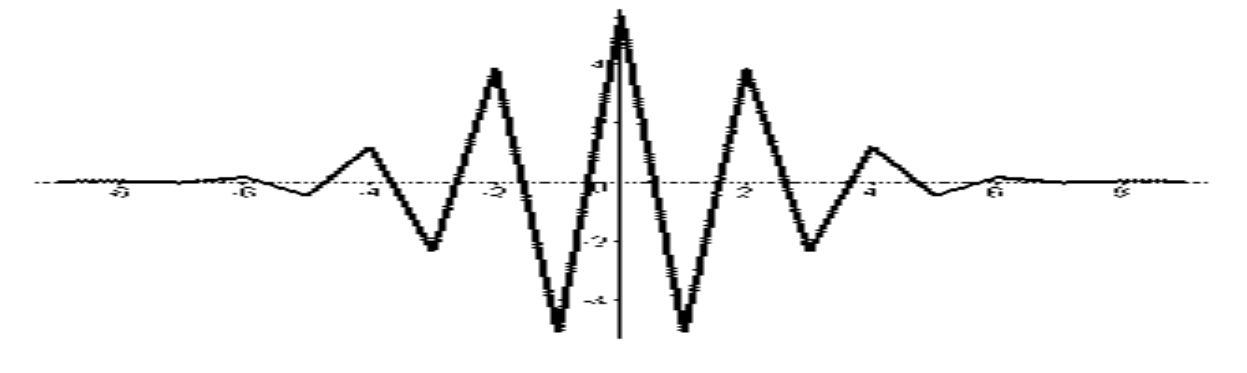
Вейвлет- функции биортогональной пары 3-5.
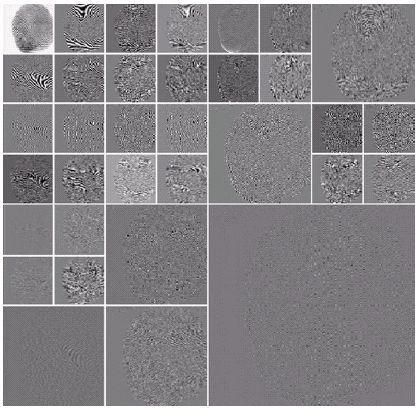
Изображение отпечатка пальца с соответствующими частотами.
Целочисленное вейвлет-преобразование.
Существует целый ряд задач, когда частотное преобразование сигнала (в нашем случае, изображение) не должно вносить ошибку округления. И это принципиально. В таком случае, все, что было изложено ранее, не подходит.Использование дискретного тригонометрического преобразования Фурье, так же, как и ортогонального (или биортогональных) вейвлет преобразования, приводит к появлению ошибок округления. Поэтому для целочисленного частотного анализа изображения было предложено использовать целочисленное вейвлет-преобразования. Традиционно для этой цели используется сепарабельном схема или схема Малла. В частности, в стандарте JPEG2000 применяется следующая конструкция.
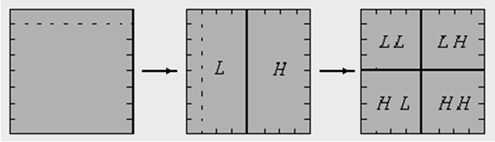
Пусть \(c^0_i \) входные данные, тогда прямой ход выглядит следующим образом \[ c_{2n}^{1}=c^{0}_{2n}-\left[\frac{c^{0}_{2n-1}+c^{0}_{2n+1}+2}{4}\right], c_{2n+1}^{1}=c^{0}_{2n+1}+\left[\frac{c^{1}_{2n}+c^{1}_{2n+2}}{2}\right], \] а обратный – \[ c_{2n+1}^{0}=c^{1}_{2n+1}-\left[\frac{c^{1}_{2n}+c^{1}_{2n+2}}{2}\right], c_{2n}^{0}=c^{1}_{2n}+\left[\frac{c^{0}_{2n-1}+c^{0}_{2n+1}+2}{4}\right]. \] Множество коэффициентов с четными индексами образует низкочастотный домен (L), а с нечетными - высокочастотный (H). Последовательное применение того же алгоритма позволяет разделить исходные данные на четыре частотных домена, из которых домен LL наиболее чувствителен к ошибке, а домен HH наименее чувствителен.
Сам процесс преобразования цветовых компонентов из равноправных (тип данных byte) к неравноправным (тип данных double или float), уже вносит ошибку округления. В случае, если точность преобразования является принципиальной, все следует сделать в целых числах. Соответствующее преобразование можно провести следующим образом
Y = [(R + 2 G + B) / 4]; U = (R - G); V = (B - G);
и обратный ходG = (Y - [(U + V) / 4]); R = U + G; B = V + G;
где [.] целая часть числа.Полученные целочисленные цветовые компоненты YUV не столь эффективны, как YCrCb или YIQ, зато лишены такой проблемы, как ошибки округления.
Заметим, что сепарабельних схема изначально ориентирована на одномерные данные, поэтому использование двумерной вейвлет-схемы для обработки изображений является лучшим. Для фильтрации данных \(p_{i, j} \) была предложена несепарабельна (что непредставимо в виде тензорного произведения одномерных) вейвлет-схема с той же сложностью, то есть с равным числом арифметических операций.
На первом этапе проводится децимация данных с четными индексами \[ s^0_{i,j}=p_{2i,2j}. \] На втором шаге по децимованим значениям строим линейные восстановления в точках с одним нечетным индексом и вычисляем соответствующие частотные коэффициенты \[ s^1_{i,j}=p_{2i+1,2j}-\left[\frac{p_{2i,2j}+p_{2i+2,2j}}{2}\right], s^2_{i,j}=p_{2i,2j+1}-\left[\frac{p_{2i,2j}+p_{2i,2j+2}}{2}\right], \] и, наконец, на третьем этапе получаем частотные коэффициенты с нечетными индексами \[ s^3_{i,j}=p_{2i,2j+1}-\left[\frac{s^0_{i,j}+s^0_{i,j+1}+s^0_{i+1,j}+s^0_{i+1,j+1}}{4}\right]-\left[\frac{s^1_{i,j}+s^1_{i,j+1}+s^2_{i,j}+s^2_{i+1,j}}{4}\right]. \] По аналогии со схемой Малла можно записать \[ HH=\left\{s^3_{i,j}\right\}, HL=\left\{s^2_{i,j}\right\}, LH=\left\{s^1_{i,j}\right\}, LL=\left\{s^0_{i,j}\right\}. \]
Полезная литература.
- Бабенко В.Ф. Быстрый алгоритм биортогонального дискретного всплеск-преобразования / В.Ф.Бабенко, А.А.Лигун, А.А.Шумейко // Математичне моделювання .— 2007 .— №1(16) .— C.18-21.
- Бабенко В.Ф. Об одном методе построения несепарабельных всплесков / В.Ф.Бабенко, А.А.Лигун, А.А.Шумейко // Математичне моделювання .— 2007 .— №2(17) .— C.35-40.
- Брейсуэлл Р. Преобразование Хартли.М.:Мир, 1990.- 175 с.
- Быстрые алгоритмы в цифровой обработке изображений / Т.С.Хуанг и др.— М.: Радио и связь, 1984 .— 224 с.
- Гонсалес Р. Цифровая обработка изображений / Р. Гонсалес, Р. Вудс . – М.: Техносфера, 2005 .– 1070 с.
- Гонсалес Р. Цифровая обработка изображений в среде MATLAB/ Р. Гонсалес, Р. Вудс, С. Эддингс . – М.: Техносфера, 2006 .– 616 с.
- Гришенцев А.Ю. Методы и модели цифровой обработки изображений / А.Ю.Гришенцев, А.Г.Коробейников .— СПб: Изд. Политех.ун-та, 2014 .— 190 с.
- Двайт Г.Б. Таблицы интегралов и другие математические формулы. / Г.Б.Двайт .— М.: Наука, 1966 .— 228 с.
- Добеши И. Десять лекций по вейвлетам, Ижевск, НИЦ "Регулярная и хаотическая динамика",2001.– 464 c.
- Залманзон Л.А. Преобразования Фурье, Уолша, Хаара и их применение в управлении, связи и других областях. / Л.А.Залманзон .— М.: Наука, 1989 .— 496 с.
- Лигун А.О. Комп’ютерна графіка (обробка та стиск зображень):навч.посіб./ А.О.Лигун, О.О.Шумейко.-Д.:Біла К.О., 2010.- 114 с.
- Малла С. Вэйвлеты в обработке сигналов / С.Малла .— М.: Мир, 2005 .— 671 с.
- Методы компьютерной обработки изображений/ Под ред. В.А.Сойфера.- М.:Физматлит, 2003.-784 с.
- Новейшие методы обработки изображений / Под ред. А.А.Потапова.- М.:Физматлит, 2008.-496 с.
- Новиков И.Я., Протасов В.Ю., Скопина М.А. Теория всплесков.- М., Физматлит, 2005. – 612 с.
- Павлидис Т. Алгоритмы машинной графики и обработки изображений / Т. Павлидис . – М.: Радио и связь, 1986 .– 400 с.
- Петухов А.П. Введение в теорию базисов всплесков. – СПб, Изд. СПбГТУ, 1999 – 132 c.
- Фурман Я.А. Цифровые методы обработки и распознавания бинарных изображений / Я.А.Фурман, А.Н.Юрьев, В.В.Яшин .— Красноярск: Изд. Краснояр. ун-та, 1992 .— 248 с.
- Чуи K. Введение в вейвлеты. – М.: Мир, 2001.
- Шумейко А. Быстрое дискретное тригонометрическое преобразование со свободным фазовым сдвигом / А.Шумейко, В.Смородский // Системні технології .— 2017 .— №4(111) .— C.46-55.
- Шумейко А.А. Интеллектуальный анализ данных (Введение в Data Mining) / А.А.Шумейко, С.Л.Сотник .— Днепропетровск: Белая Е.А., 2012 .— 212 с.
- Шумейко А.А. Применение несепарабельной вейвлет-схемы для стеганографической защиты данных / А.А.Шумейко, А.И.Пасько// Вісник східноукраїнського національного університету імені Володимира Даля.— 2008.— №8(126) .— C.50-55.
- Ярославский Л.П. Введение в цифровую обработку изображений. — М.: Сов. радио, 1979. — 312 с.
- Hartley,R."A more symmetrical Fourier analysis applied to transmission problems," Proc. IRE 30, 144–150 (1942).
- Mallat S.A. Theory for Multiresolution Signal Decomposition: The Wavelet Representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 11, No. 7, July 1989, p. 674-693.
- Shumeiko А. Discrete trigonometric transform and its usage in digital image processing / А.Shumeiko, V.Smorodskyi // Econtechmod. An International Quarterly Journal .— 2017 .— №4(6) .— C.21-26.